
 ...
...
前段时间想做一款像素风的游戏,中文像素字体就是一个绕不过去的问题。这里记录下我制作 12 像素字体的过程。
使用的软件是 fontforge:https://fontforge.org/en-US/
自己一个字一个字的做是不可能自己做的,所以在网上找到了两个开源的字体库
1. M+ BITMAP FONTS
https://mplus-fonts.osdn.jp/mplus-bitmap-fonts/download/index.html
这是来自日本的完全免费字体,看着还蛮好看,有一部分的中文部分。
2. HZK-12
https://github.com/aguegu/BitmapFont
覆盖 GB2312 的中文 12 像素字体
制作思路
灵感来自 ipix 中文像素字体的制作 我在原作的基础上进行了一些修改。原作是将字模导出为 png 然后 Potrace 转化成 svg 图片, 最后再把 SVG 图片导入 FontForge 中就制作。
我是直接调用了命令行的 fontforge, 使用 python 脚本读取字模信息,然后调用 fontforge 的矩形绘制函数,把每个像素点绘制成一个 100x100的正方形。省去了一些中间步骤,所以效率提升了很多,制作过程只用了几分钟就完成了。当然摸索这个方法的时间也用了三个晚上,好在以后重新制作的时间缩短到了几分钟。这里记录下详细的制作步骤,以及分享下源码。
1. 安装 fontforge 并添加支持库 bdflib
bdf 支持库是为了解析 M+ BITMAP FONTS ,hzk12 不需要额外插件。
fontforge 安装步骤省略,fontforge 会默认安装上 python 运行环境到软件目录下面 。
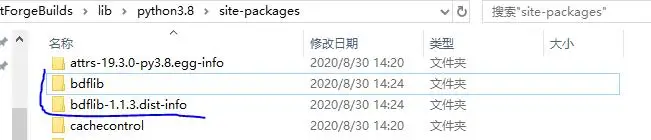
下载 bdflib 的 whl 文件解压到
FontForgeBuilds\lib\python3.8\site-packages
目录下就安装好了。
 ...
...
2. 利用 Hzk12 生成 fontforge 工程
新建一个文件夹使用 vscode 打开, 新建 python 脚本命名为 hzk_to_sfd.py,安装 python 插件,设置 python 目录为 fontforge 下的 python 环境 如图所示:
 ...
...
源码部分:
import fontforgeimport binascii
KEYS = [ 0x80, 0x40, 0x20, 0x10, 0x08, 0x04, 0x02, 0x01]
sdf_path = "HZK12.sfd"
hzk_path = "C:/Users/lo/Downloads/HZK/HZK12"
gb2312_path = "C:/Users/lo/Downloads/HZK/gb2312.txt"
def Draw(font, ch, rect_list):
gb2312 = ch.encode('gb2312')
hex_str = binascii.b2a_hex(gb2312)
result = str(hex_str, encoding='utf-8')
area = eval('0x' + result[: 2]) - 0x80
index = eval('0x' + result[ 2:]) - 0x80
ioj = (area << 8) + index
# print(ch, gb2312, hex_str, result, ioj)
glyph = font.createMappedChar(ioj)
pen = glyph.glyphPen
y = 11
max_x = 0
for row in rect_list:
y = y - 1
x = - 1
for i in row:
x = x + 1
if i:
pen.moveTo(( 100* x , 100* y ))
pen.lineTo(( 100* x , 100* y + 100))
pen.lineTo(( 100* x + 100, 100* y + 100))
pen.lineTo(( 100* x + 100, 100* y ))
pen.closePath
max_x = max(max_x,x)
# print("#")
# else:
# print(" ")
# print("\n")
pen = None
glyph.removeOverlap
glyph.width = max_x* 100+ 200
def draw_glyph(ch):
rect_list = * 12
for i in range( 12):
rect_list.append([] * 16)
# 获取中文的 gb2312 编码,一个汉字是由 2 个字节编码组成
gb2312 = ch.encode('gb2312')
# 将二进制编码数据转化为十六进制数据
hex_str = binascii.b2a_hex(gb2312)
# 将数据按 unicode 转化为字符串
result = str(hex_str, encoding='utf-8')
# 前两位对应汉字的第一个字节:区码,每一区记录 94 个字符
area = eval('0x' + result[: 2]) - 0xA0
# 后两位对应汉字的第二个字节:位码,是汉字在其区的位置
index = eval('0x' + result[ 2:]) - 0xA0
# 汉字在 HZK16 中的绝对偏移位置,最后乘 24 是因为字库中的每个汉字字模都需要 24 字节
offset = ( 94* (area- 1) + (index- 1)) * 24
font_rect = None
# 读取 HZK16 汉字库文件
with open(hzk_path, "rb") as f:
# 找到目标汉字的偏移位置
f.seek(offset)
# 从该字模数据中读取 24 字节数据
font_rect = f.read( 24)
# font_rect 的长度是 24,此处相当于 for k in range(16)
for k in range(len(font_rect) // 2):
# 每行数据
row_list = rect_list[k]
for j in range( 2):
for i in range( 8):
asc = font_rect[k * 2+ j]
# 此处&为 Python 中的按位与运算符
flag = asc & KEYS[i]
# 数据规则获取字模中数据添加到 16 行每行中 16 个位置处每个位置
row_list.append(flag)
return rect_list
def OpenGBK:
f = open(gb2312_path, 'r', encoding='UTF-8')
line = f.readline
for index, ch in enumerate(line):
if ch == "\n":
continue
print(index, end=' ')
print(ch)
f.close
def Start:
font = fontforge.font # Open a font
font.encoding = "gb2312"
font.ascent = 1200
f = open(gb2312_path, 'r', encoding='UTF-8')
line = f.readline
while line:
for index, ch in enumerate(line):
if ch == "\n":
continue
print(ch)
rect = draw_glyph(ch)
Draw(font, ch, rect)
line = f.readline
font.save(sdf_path)
f.close
Start
这里依赖两个文件 HZK12 和 gb2312.txt ,可以在 源码中下载,在 Vscode 中运行脚本,或者在终端输入:
"c:/Program Files (x86)/FontForgeBuilds/bin/ffpython.exe" c:/Users/lo/ Downloads/HZK/hzk_to_sfd.py#当然这里的 ffpython.exe 文件和 python 文件的路径需要修改。
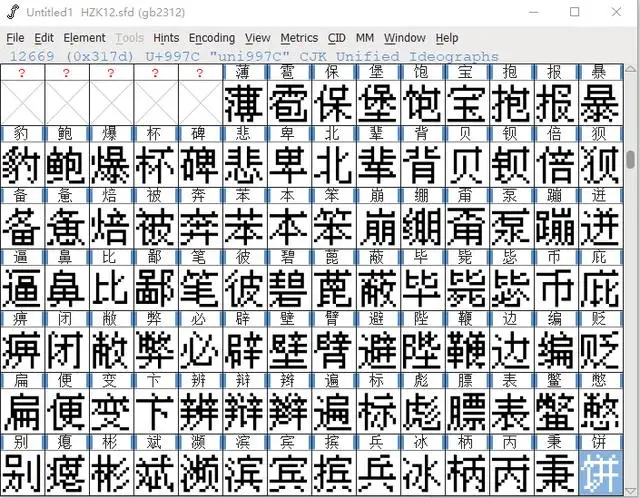
就能生成一个 hzk12.sfd的文件,双击使用 fontforge 打开。看看效果。
 ...
...
还行 文字没有错位(hzk12 没有前面的英文字模,所以看效果需要向下多翻一点)下面就来添加英文字模进来
3. 利用 M+ BITMAP FONTS 生成 fontforge 工程
我这里选择的是 mplus_jf12r.bdf文件作为字模,也可以使用其他的。
与第二步相同新建一个名为 bdf_to_sdf.py的文件,这里依赖了第一步中安装的bdflib插件。
from bdflib import writer
import fontforge
def OpenBDF(path):
with open(path, "rb") as handle:
return reader.read_bdf(handle)
def Start:
bdf_font = OpenBDF("C:/Users/lo/Downloads/HZK/mplus_jf12r.bdf")
sdf_font = fontforge.font
sdf_font.encoding = "jis208"
sdf_font.ascent = 1200
for bdf_glyph in bdf_font.glyphs:
# bdf_glyph = bdf_font[12321]
x = - 1
y = 10
print(bdf_glyph.codepoint)
glyph = sdf_font.createMappedChar(bdf_glyph.codepoint)
pen = glyph.glyphPen
for ch in bdf_glyph.__str__:
if ch == '\n':
y = y - 1
x = - 1
print("")
if ch == '#' :
pen.moveTo(( 100* x , 100* y ))
pen.lineTo(( 100* x , 100* y + 100))
pen.lineTo(( 100* x + 100, 100* y + 100))
pen.lineTo(( 100* x + 100, 100* y ))
pen.closePath
print("#",end=" ")
else:
print(" ",end=" ")
x = x + 1
pen = None
glyph.removeOverlap
# break
# sdf_font.autoWidth
sdf_font.save("mplus_jf12r.sfd")
Start
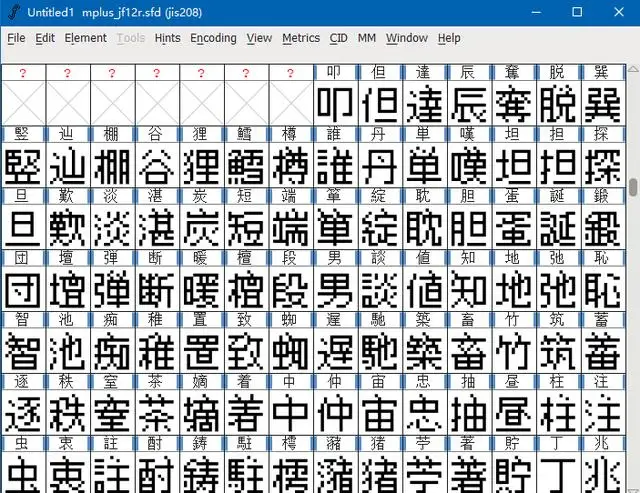
这里使用的文件同 mplus_jf12r.bdf 样放在了源码中。和第二步一样的运行方式,运行后得到一个 mplus_jf12r.sfd 的 fontforge 工程。
 ...
...
也没有错位,太棒了。第 4 步就是把这两个字体合并一下了。
4. 合并字体
hzk12 和 mplus bitmap 中有很多重合的字,所以有两种合并方式,一个是重合的部分使用 hzk12 的字模,一个是使用 mplus 的。我选择保留 mplus 的重合部分。
由于两者编码格式不同所以先统一下编码格式,一个是 gb2312 一个是 jis208,所以我这全都设置成 Unicode Full 的格式。(fontforge 下的菜单 Encoding->reencode->ISO 10646-1 ( Unicode, Full ))。然后在打开 Mplus-jf12r 的 fontforge 的窗口中 选择菜单Element->Merge Fonts然后选择hzk12.sfd文件,然后会弹出一个对话框询问 是否用导入的 graph 替换本工程的同位置 graph,这里选择NO,就是使用 mplus 的重合部分。
选择英文和符号部分 调整下 Graph 的宽度 ,推荐 菜单 Metrics->Auto Width。
推荐按下
下一步生成 ttf 字体文件。生成之前可以先编辑下字体信息, 菜单 Element->font info,这里不介绍了。
5. 生成 ttf 文件
菜单 File->Generate Fonts
设置下 TrueType 就可以点击 Generate了。这里会有对话框提示:“有重合的点或者面”, 我还没有找到比较好的办法消除,但是并不影响使用,所以就没有再多处理。依然点击Generate生成。
好了现在打开字体看下效果。
...还行吧 就是符号的部分不是很好看,也可以重新找点好看的字模用上面的方法替换下,我觉得也能用就没换了,有需要可以自己动手了,接着看下在 Unity 中的效果怎么样吧。
...效果不错 没有错位。
结束。
源码及参考
源码以及 TTF 文件: https://github.com/Luckeee/mplus_hzk_12
参考:
ipix 中文像素字体的制作https://indienova.com/u/purestudio/blogread/20097
如何将点阵汉字矢量化https://indienova.com/indie-game-development/vectorize-chinese-bitmap-font/
Python 解析 HZK16https://zhuanlan.zhihu.com/p/54931969
