
表1. ELF文件类型分类
ELF文件类型 说明 实例 Relocatable File 可重定位文件 未链接之前的ELF文件,可用于链接可执行文件或静态链接库 Linux下的".o"文件,Windows下".obj"文件 Executable File 可执行文件 最终的可执行程序 如Linux下"/bin"目录下文件,Windows的".exe"文件 Shared Objected File 共享目标文件 一种是可用于静态链接文件,另一种是程序运行中被动态链接文件 如Linux下的".a"和".so"文件,Windows的dll文件 Core Dump File 核心转储文件 进程意外终止时,保存进程地址空间的内容以及其他信息 Linux下的core dump一、前言
在早期的UNIX中,可执行文件格式为a.out格式,由于其格式简单,随着共享库概念的出现被COFF格式取代,后来Linux和Windows基于COFF格式,分别制定了ELF和PE格式,我们日常使用的".exe"文件".lib",".dll"文件就属于PE文件的一种;Linux平台下的可执行文件,中间目标文件".o"以及静态库".a"和动态链接库".so"文件属于ELF文件,本节主要讲解中间目标文件(Relocatable File in ELF)这一ELF类型的文件结构,因为这是编译器将源代码经过预编译,编译,汇编后得到的第一层ELF文件,目标文件经过链接后才能成为真正在Linux下运行的可执行文件,这一类型会在后续blog中讲解。
本文所有测试结果在以下平台得出 ,不同的软件系统与硬件架构在输出结果上会稍有不同,但原理一致。
qi@qi:~$ uname -a Linux qi 5.4.0-89-generic #100~18.04.1-Ubuntu SMP Wed Sep 29 10:59:42 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux
Reference:
[1] 《程序员的自我修养,链接、装载与库》,俞甲子 石凡 潘爱民
二、测试用例
我们以一段具有代表性的C文件来作为测试源码,如下,该程序中包含了各种类型的变量以及函数,这些变量或者函数符号经过汇编生成中间目标文件后将被保存在不同的ELF段里。
int printf( const char* format, ... ); // 外部函数声明
int global_init_var = 84; // 全局已赋值变量
int global_uninit_var; // 全局未初始化变量
void func1( int i ) {
printf("%d\n", i);
}
int main(void) {
static int static_var = 85; // 局部静态已赋值变量
static int static_var2; // 局部静态未初始化变量
int a = 1; // 局部已赋值变量
int b; // 局部未初始化变量
func1( static_var + static_var2 + a + b);
return a;
}
我们使用gcc编译出汇编文件,中间目标文件,以及最终可执行文件,最后使用"file"工具查看文件类型,使用"tree"查看生成的文件大小 :
$ ls SimpleSection.c $ gcc -S SimpleSection.c && gcc -c SimpleSection.c -o SimpleSection.o && gcc SimpleSection.c -o SimpleSection $ tree -sp . ├── [-rwxrwxr-x 8512] SimpleSection ├── [-rw-rw-r-- 395] SimpleSection.c ├── [-rw-rw-r-- 1936] SimpleSection.o └── [-rw-rw-r-- 1336] SimpleSection.s $ file * SimpleSection: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 3.2.0, BuildID[sha1]=da891be2d625e27300a0a9682a57fb6cf6563d82, not stripped SimpleSection.c: C source, ASCII text SimpleSection.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), not stripped SimpleSection.s: assembler source, ASCII text
可以看到,文件"SimpleSection"和"SimpleSection.o"均为ELF-64文件,但是类型不一样,"SimpleSection.o"文件大小为1936个字节。后文使用sublime text以16进制查看ELF目标文件。
三、目标文件ELF结构
ELF文件总体结构可以用图1表示,图左为"SimpleSection.o"文件的前一部分以十六进制表示的内容,图中间一层层的字段(定义:每种字段存储不同类型的内容)就是ELF结构的内容层次了,在目标文件的开头为一个长度为64(0x40)字节的ELF头,只要分析ELF表头内存储的信息,可以得出段表"Section Header table"(在图的最顶层的那个段)在整个目标文件中的偏移,而段表是一个元素为"Elf64_Shdr"结构体类型的数组,它的元素的数量正好是图中间那些字段的数量,也就是它的每个元素存储了中间一些字段如".text",".symtab"等字段的信息,这些信息包括字段名,大小等等属性。所以概括的来说,通过读取ELF头,可以得到段表,然后通过读取段表中各个字段元素,就可以得出各个字段的信息了。那么读到这里,ELF结构轮廓已然清晰,接下来就是分析ELF文件各个字段的具体用途,以及某些字段是具体如何关联才使得链接器能够完全理解这个文件。
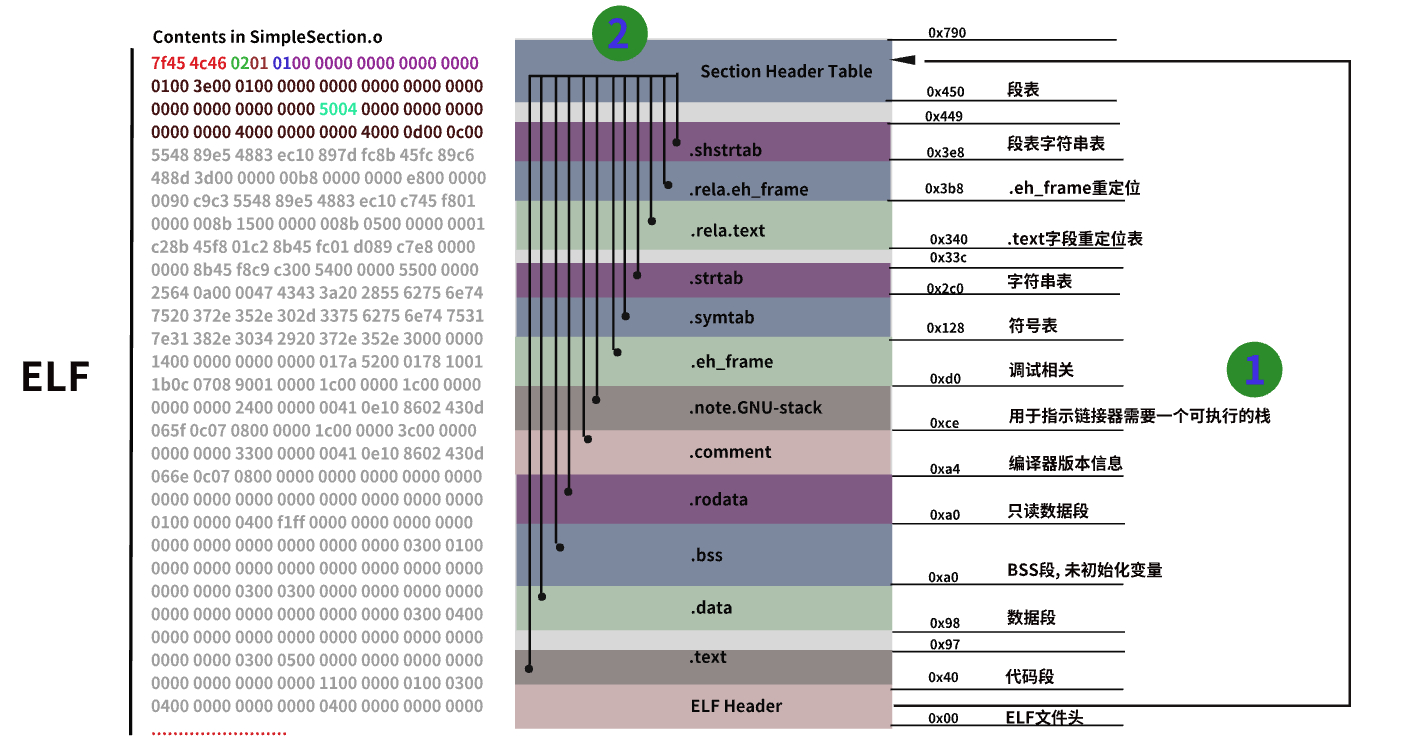
图1 ELF文件结构图
1 .text字段:用于保存程序中的代码片段
2 .data字段:用于保存已经初始化的全局变量和局部变量
3 .bss字段:用于保存未初始化的全局变量和局部变量
4 .rodata:顾名思义,保存只读的变量
5 .comment:保存编译器版本信息
6 .symtab:符号表,各个目标文件链接的接口
7 .strtab:字符串表,保存符号的名字,因为各个字符串大小不一,所以统一把所有字符串放到这个段里,后续其他段通过某个符号在字符串标中的偏移可以取到符号。
8 .rela.text:因为程序声明使用了未在程序内部定义的函数或者变量,所以需要等到链接时(定义在别的目标文件或者库里)对这个符号的地址进行重新定位,不然会引用到错误的地址。
9 .shstrtab:和strtab类似,不过保存是段名,也就是说里面保存的字符串是所有段的名字
10 Section Header Table:段表,保存了所有段的信息,本身通过Elf头找到,可以解析出所有段的位置。
在你还没掌握肉身解码ELF文件之前,你可能需要一些工具才能得出目标文件中有什么字段,每个字段有多少字节等等信息,我们可以借助"objdump"和"readelf"来查看目标文件内的细节 : 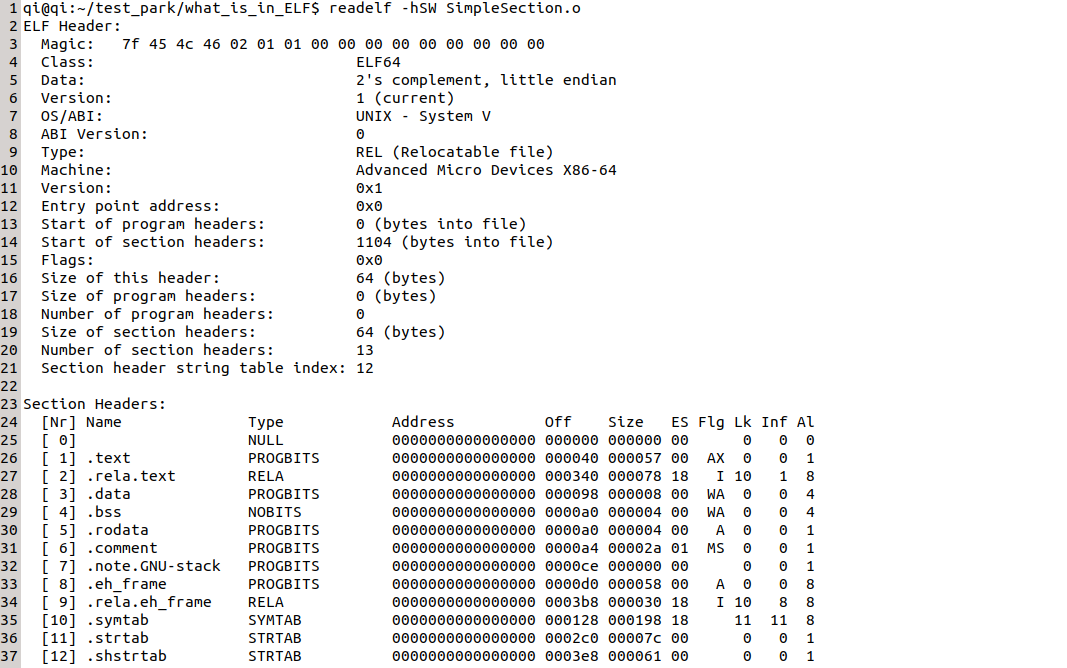
段表元素类型:Elf64_Shdr
typedef struct
{
Elf64_Word sh_name; /* Section name (string tbl index) */
Elf64_Word sh_type; /* Section type */
Elf64_Xword sh_flags; /* Section flags */
Elf64_Addr sh_addr; /* Section virtual addr at execution */
Elf64_Off sh_offset; /* Section file offset */
Elf64_Xword sh_size; /* Section size in bytes */
Elf64_Word sh_link; /* Link to another section */
Elf64_Word sh_info; /* Additional section information */
Elf64_Xword sh_addralign; /* Section alignment */
Elf64_Xword sh_entsize; /* Entry size if section holds table */
} Elf64_Shdr;
Elf文件头类型:Elf64_Ehdr
typedef struct
{
unsigned char e_ident[EI_NIDENT]; /* Magic number and other info */
Elf64_Half e_type; /* Object file type */
Elf64_Half e_machine; /* Architecture */
Elf64_Word e_version; /* Object file version */
Elf64_Addr e_entry; /* Entry point virtual address */
Elf64_Off e_phoff; /* Program header table file offset */
Elf64_Off e_shoff; /* Section header table file offset */
Elf64_Word e_flags; /* Processor-specific flags */
Elf64_Half e_ehsize; /* ELF header size in bytes */
Elf64_Half e_phentsize; /* Program header table entry size */
Elf64_Half e_phnum; /* Program header table entry count */
Elf64_Half e_shentsize; /* Section header table entry size */
Elf64_Half e_shnum; /* Section header table entry count */
Elf64_Half e_shstrndx; /* Section header string table index */
} Elf64_Ehdr;
上文中我们说到可以通过Elf头得到段表在文件中的位置从而可以找到段表,保存这个偏置的信息就保存在结构体 "Elf64_Ehdr"中的成员 "e_shoff" 中,我们回过头来看Elf表头的内容,使用sublime text打开目标文件,观察文件头前64个字节也就是Elf文件头的大小:
7f45 4c46 0201 0100 0000 0000 0000 0000 0100 3e00 0100 0000 0000 0000 0000 0000 0000 0000 0000 0000 5004 0000 0000 0000 0000 0000 4000 0000 0000 4000 0d00 0c00
可以看到,在第41个字节开始的8个字节(成员e_shoff为Elf64_Off类型,是uint64_t的typedef)为 "5004000000000000",由于是little endian,所以转化成十进制就是0x0450=1104,正好和readelf输出的偏移一样。
我们再来观察由Elf头得到的段表,也就是文件从第1105个字节开始的段,前128个字节(包含了NULL和.text字段的信息)如下:0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 2000 0000 0100 0000 0600 0000 0000 0000 0000 0000 0000 0000 4000 0000 0000 0000 5700 0000 0000 0000 0000 0000 0000 0000 0100 0000 0000 0000 0000 0000 0000 0000
因为第一个字段为NULL,所以64个字节全为0,接下来的一个字段就是.text字段,对比一下 "Elf64_Shdr"结构体的定义,刚好是64个字节,其中成员 "sh_offset" 表示该段在文件中的偏移,该结构体的第25-32这8个字节为0x40,是"sh_offset"的值,而该结构体的第23-40这8个字节为0x57,是 "sh_size" 的值,正好是偏置0x40,大小0x57,和readelf工具的输出一致。
等等,我为什么知道这个字段是叫".text",请看 "Elf64_Ehdr" 结构体的第一个成员,该成员的值表示字段名在段表字符串表中的下标,为0x20,我们根据0x20,到字段 ".shstrtab" 中找到第33个字节开始,将16进制码转化为ASCII码,就可以知道该段的名字了,说干就干,但是现在每一个字段的名字都还不知道,也就不知道这12个字段里哪一个才是 ".shstrtab", Elf Header结构体 "Elf64_Ehdr" 的最后一个变量 "e_shstrndx" 告诉了我们该段在段表数组中的下标,我们看目标文件前64个字节中的最后两个字节为0x000c=12,也就是说,段表数组的最后一个元素就是我们要找的 ".shstrtab" 字段了,这个元素应该是目标文件的最后64个字节,而这64个字节中的第25-32这8个字节为0x03e8,也就是说 ".shstrtab" 字段的内容从第0x3e8+1个字节开始,我们用sublime text打开目标文件,找到第1001个字节,往后走0x20=32个字节:
**** **** **** **** 002e 7379 6d74 6162 002e 7374 7274 6162 002e 7368 7374 7274 6162 002e 7265 6c61 2e74 6578 7400 2e64 6174 6100 2e62 7373 002e 726f 6461 7461 002e 636f 6d6d 656e 7400 2e6e 6f74 652e 474e 552d 7374 6163 6b00 2e72 656c 612e 6568 5f66 7261 6d65 00** **** **** ****
后面的5个字节为 "2e 74 65 78 74",转换为ASCII正好为 ".text",OK,大功告成。
使用objdump工具,我们可以看到各个字段的内容,上文中objdump输出了".text"等字段的内容,如".text"字段输出了0x57个字节,与readelf的输出一致。 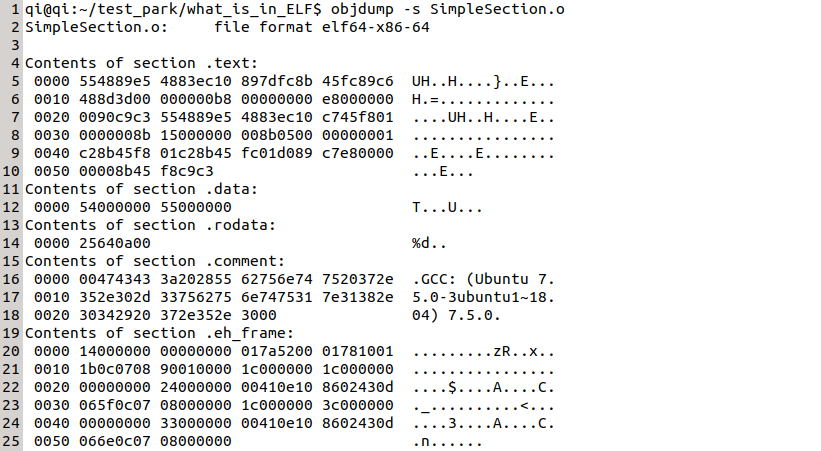
四、不放过ELF文件的每一个字节
再更...
