")
文章目录
一、环境与工具 二、学爬虫必备知识 三、requests体验 四、get 请求 3.1 基础讲解一 3.3 基础讲解二 3.2 基础讲解三 3.4 获取cookie 3.5 获取请求头 3.6 添加请求头 3.5 知乎爬取+反扒技术 3.6 抓取二进制数据 3.6.1 示例一 3.6.2 示例二 3.7 美女私房照爬取( 准备发车) 四、 POST 请求 4.1 数据表单提交 4.2 添加请求头 4.3 提交json 4.4 普通文件上传 四、粉丝福利 五、总结一、环境与工具
环境:jupyter
如果你没有安装该工具和不会使用,请看这一篇文章:pycharm安装配置与使用详细教程
你可能还会需要这两篇文章:
1-亲测jupyter打不开浏览器
2-设置默认打开文件夹
模块安装:
!pip install requests
演示一下安装:
安装成功:

二、学爬虫必备知识
如果你python基础都不会,建议你先看看我写了几十万字的python基础专栏:python全栈基础教程
我的基础专栏包括最基本的基础,re正则表达式,画图,文件处理,django,mysql操作处理等,如果你基础都不会,建议你先收藏本篇内容,去学完我写的基础,再来看本篇文章。
三、requests体验
以百度为例子:
import requests
r = requests.get('https://www.baidu.com/')
print(type(r))
print(r.status_code)
print(type(r.text))
print(r.text)
print(r.cookies)
打印结果如下:

得到一个 Response 对象,然后分别输出了 Response 的类型、状态码、响应体的类型、内容以及 Cookies。在这里仅仅是体验,如果你看不懂,并没有关系。
四、get 请求
3.1 基础讲解一
现在以百度为例子:
https://www.baidu.com/
我们用get请求网址,打印txt则获取到百度页面源码:
import requests
r = requests.get('https://www.baidu.com/')
print(r.text)
运行:

为什么我这里只演示了百度?因为这个不会被反扒,如果被反扒,则会返回为空。大家可以试试别的网址,比如我的博客地址,基本返回为空。不必担心,后续教大家反扒。
3.3 基础讲解二
我们以CSDN我自己的博客为例:
这里就直接使用requests模块的get函数直接来获取(get和urlopen是相同的),主要是这个更方便:
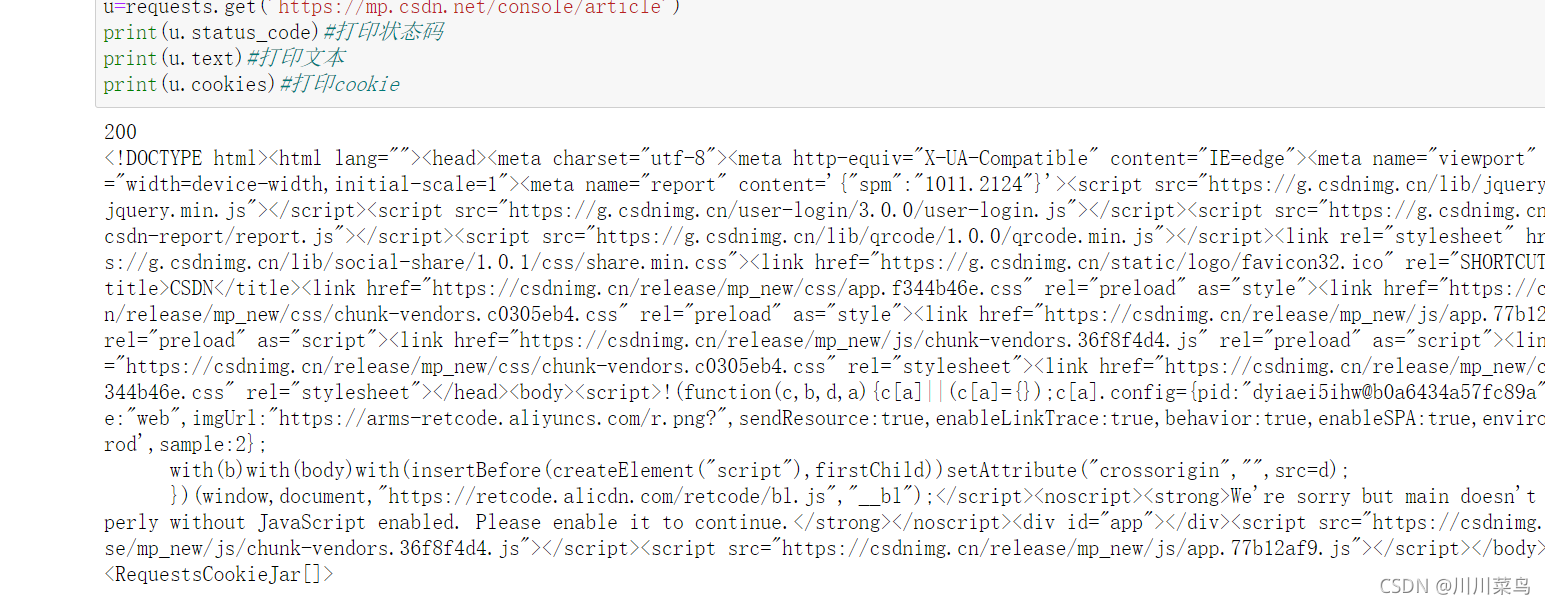
import requests
u=requests.get('https://mp.csdn.net/console/article')
print(u.status_code)#打印状态码
print(u.text)#打印文本
print(u.cookies)#打印cookie
运行:
再举例子:
import requests
r=requests.post('https://www.csdn.net/?spm=1011.2124.3001.5359')
s=requests.put('https://www.csdn.net/?spm=1011.2124.3001.5359')
print(r.status_code)
print(r.text)
print(s.status_code)
print(s.text)
运行:
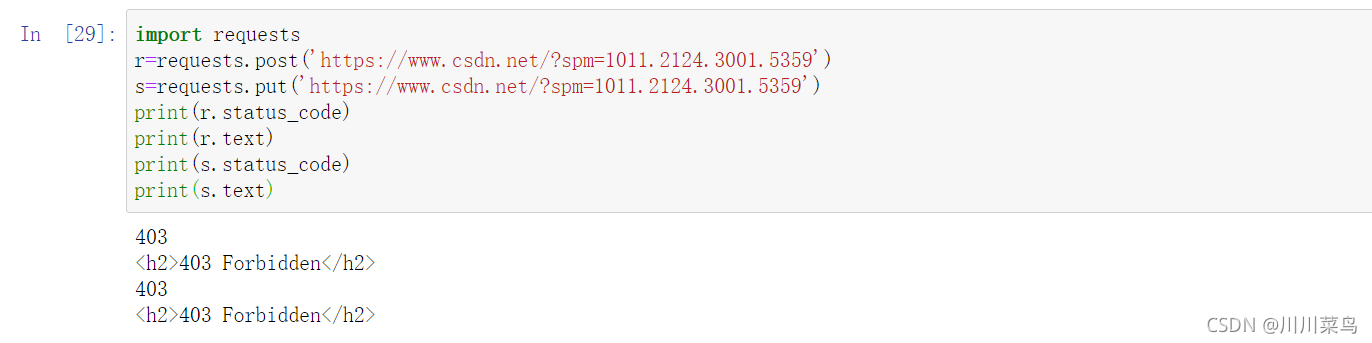
虽然请求失败但不影响,主要是介绍下用requests模块的话,可以很简单的方式请求,比如说put,post,delete这些之间换一下就换了一个请求方法。这里请求失败因为我们被反扒了。
3.2 基础讲解三
首先,构建一个最简单的 GET 请求,请求的链接为 http://httpbin.org/get,该网站会判断如果客户端发起的是 GET 请求的话,它返回相应的请求信息.
代码:
import requests
r = requests.get('http://httpbin.org/get')
print(r.text)
运行:
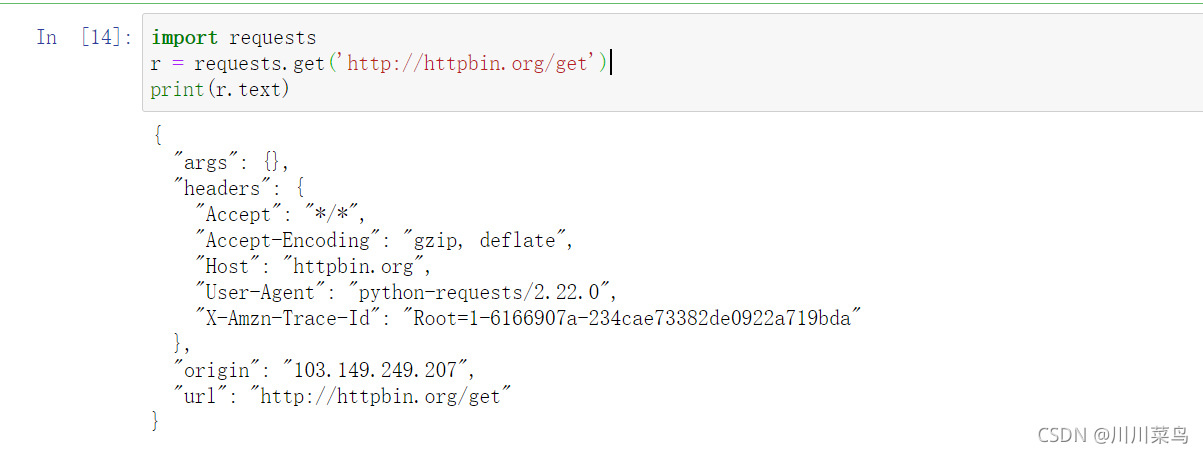
可以发现,我们成功发起了 GET 请求,返回结果中包含请求头、URL、IP 等信息。
那么,对于 GET 请求,如果要附加额外的信息,一般怎样添加呢?比如现在想添加两个参数,其中 name 是 germey,age 是 22。要构造这个请求链接,是不是要直接写成:
r = requests.get('http://httpbin.org/get?name=germey&age=22')
这同样很简单,利用 params 这个参数就好了,示例如下:
import requests
data = {
'name': 'germey',
'age': 22
}
r = requests.get("http://httpbin.org/get", params=data)
print(r.text)
运行:
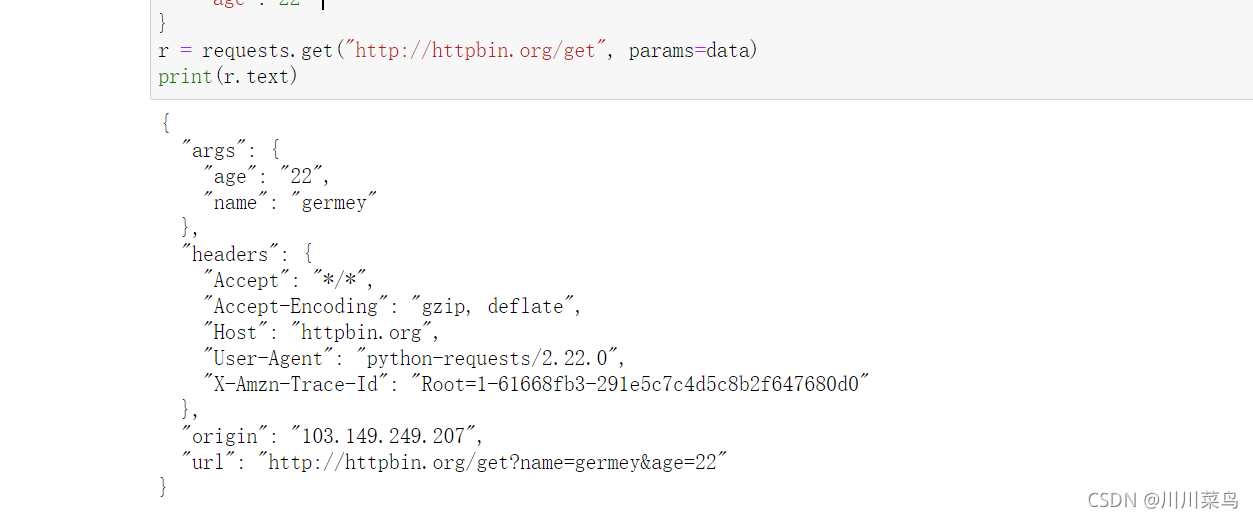
通过返回信息我们可以判断,请求的链接自动被构造成了:
http://httpbin.org/get?age=22&name=germey
另外,网页的返回类型实际上是 str 类型,但是它很特殊,是 JSON 格式的。所以,如果想直接解析返回结果,得到一个字典格式的话,可以直接调用 json 方法。示例如下:
import requests
r = requests.get("http://httpbin.org/get")
print(type(r.text))
print(r.json())
print(type(r.json()))
运行:

可以发现,调用 json 方法,就可以将返回结果是 JSON 格式的字符串转化为字典。
3.4 获取cookie
import requests
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36'
}#请求头
url='https://www.csdn.net/?spm=1011.2124.3001.5359'
r=requests.get(url=url,headers=headers)
print(r.cookies)#直接打印
运行:

3.5 获取请求头
手动获取:
点击右键,选择检查,再选择network,刷新一下,随机选其中一个内容,如下:
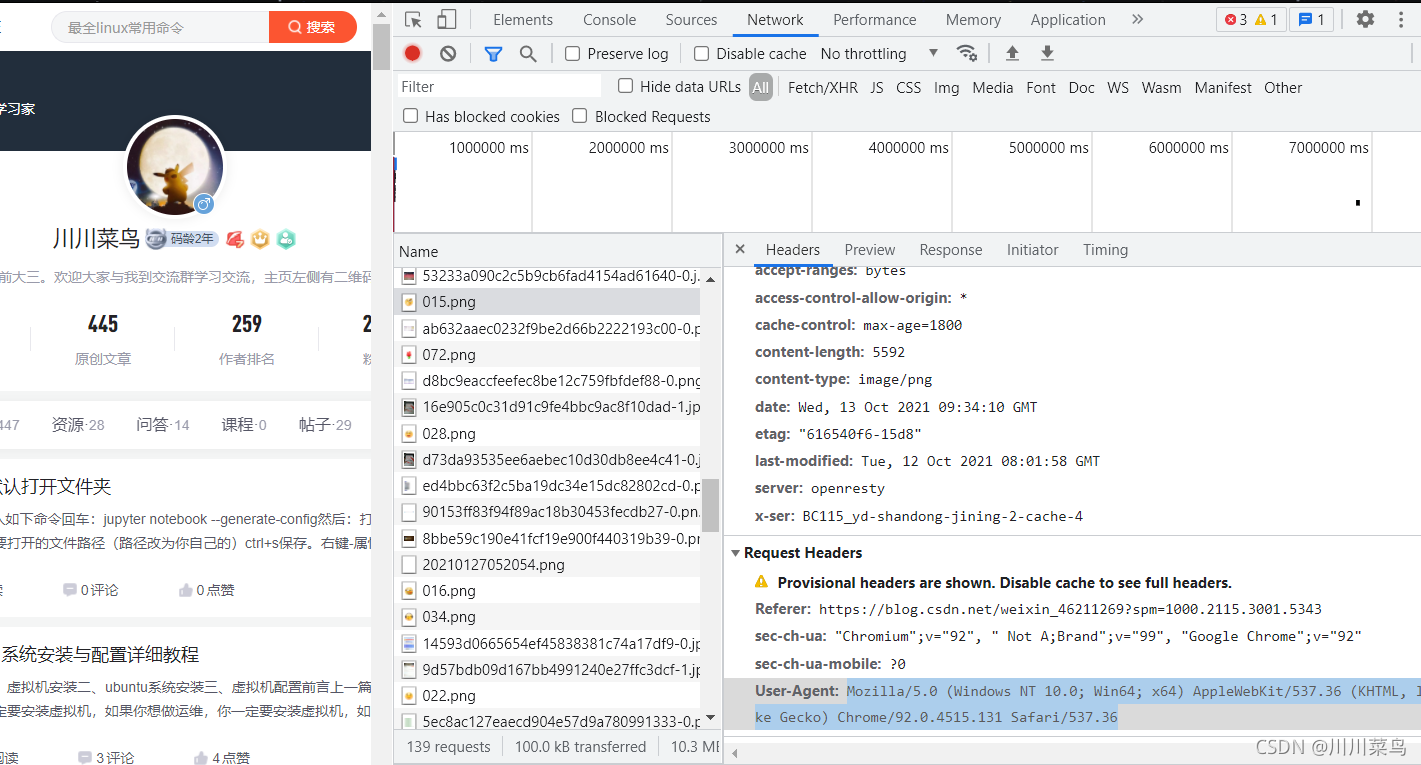
复制出来就行。
3.6 添加请求头
我们也可以通过 headers 参数来传递头信息。比如,在下面我们的面 “知乎” 的例子中,如果不传递 headers,就不能正常请求,请求结果为403:
import requests
r = requests.get("https://www.zhihu.com/explore")
print(r.text)
运行:
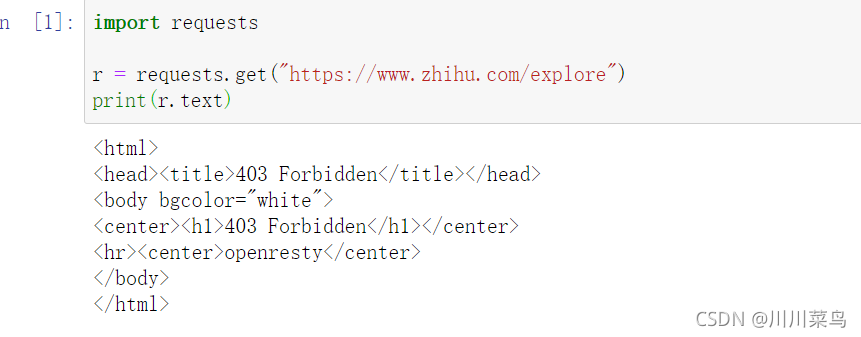
但如果加上 headers 并加上 User-Agent 信息,那就没问题了:
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'
}
r = requests.get("https://www.zhihu.com/explore", headers=headers)
print(r.text)
运行:
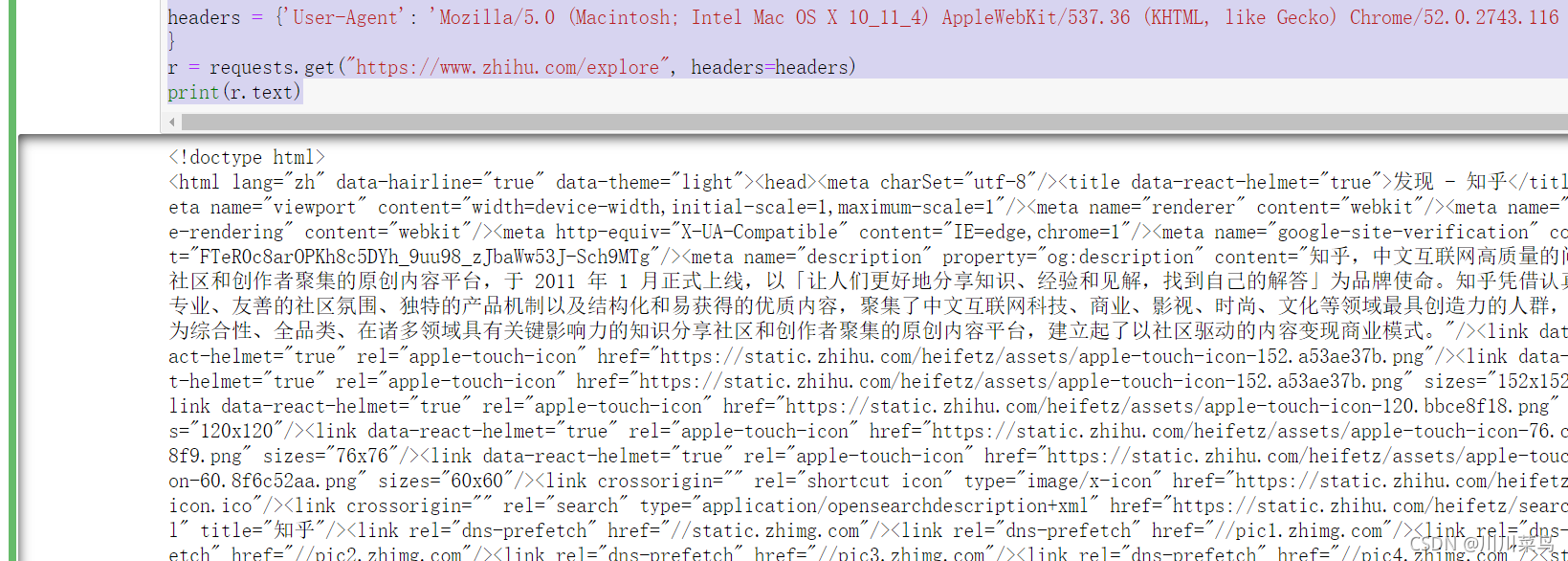
可以看到加请求头成功了。
为什么加请求头?可以模拟正常浏览器,防止被反扒。
3.5 知乎爬取+反扒技术
先获取cookies:
import requests
headers={
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11'
}
url='http://www.zhihu.com'
r=requests.get(url=url,headers=headers)
print(r.cookies)
运行:

或者登录知乎,找到cookie:
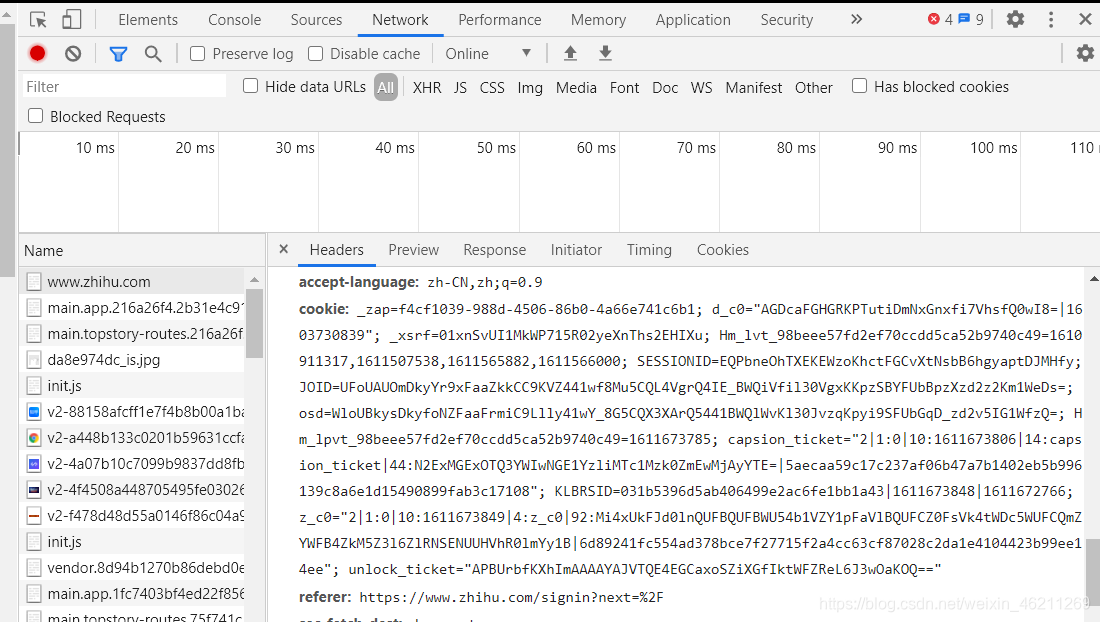
用这里的cookie来获取网页:
import requests
headers={
'Cookie':'_zap=f4cf1039-988d-4506-86b0-4a66e741c6b1; d_c0="AGDcaFGHGRKPTutiDmNxGnxfi7VhsfQ0wI8=|1603730839"; _xsrf=01xnSvUI1MkWP715R02yeXnThs2EHIXu; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1610911317,1611507538,1611565882,1611566000; SESSIONID=EQPbneOhTXEKEWzoKhctFGCvXtNsbB6hgyaptDJMHfy; JOID=UFoUAUOmDkyYr9xFaaZkkCC9KVZ441wf8Mu5CQL4VgrQ4IE_BWQiVfil30VgxKKpzSBYFUbBpzXzd2z2Km1WeDs=; osd=WloUBkysDkyfoNZFaaFrmiC9Llly41wY_8G5CQX3XArQ5441BWQlWvKl30JvzqKpyi9SFUbGqD_zd2v5IG1WfzQ=; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1611673785; capsion_ticket="2|1:0|10:1611673806|14:capsion_ticket|44:N2ExMGExOTQ3YWIwNGE1YzliMTc1Mzk0ZmEwMjAyYTE=|5aecaa59c17c237af06b47a7b1402eb5b996139c8a6e1d15490899fab3c17108"; KLBRSID=031b5396d5ab406499e2ac6fe1bb1a43|1611673848|1611672766; z_c0="2|1:0|10:1611673849|4:z_c0|92:Mi4xUkFJd0lnQUFBQUFBWU54b1VZY1pFaVlBQUFCZ0FsVk4tWDc5WUFCQmZYWFB4ZkM5Z3l6ZlRNSENUUHVhR0lmYy1B|6d89241fc554ad378bce7f27715f2a4cc63cf87028c2da1e4104423b99ee14ee"; unlock_ticket="APBUrbfKXhImAAAAYAJVTQE4EGCaxoSZiXGfIktWFZReL6J3wOaKOQ=="',
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'host':'www.zhihu.com',
}
url='http://www.zhihu.com'
r=requests.get(url=url,headers=headers)
print(r.text)
运行:
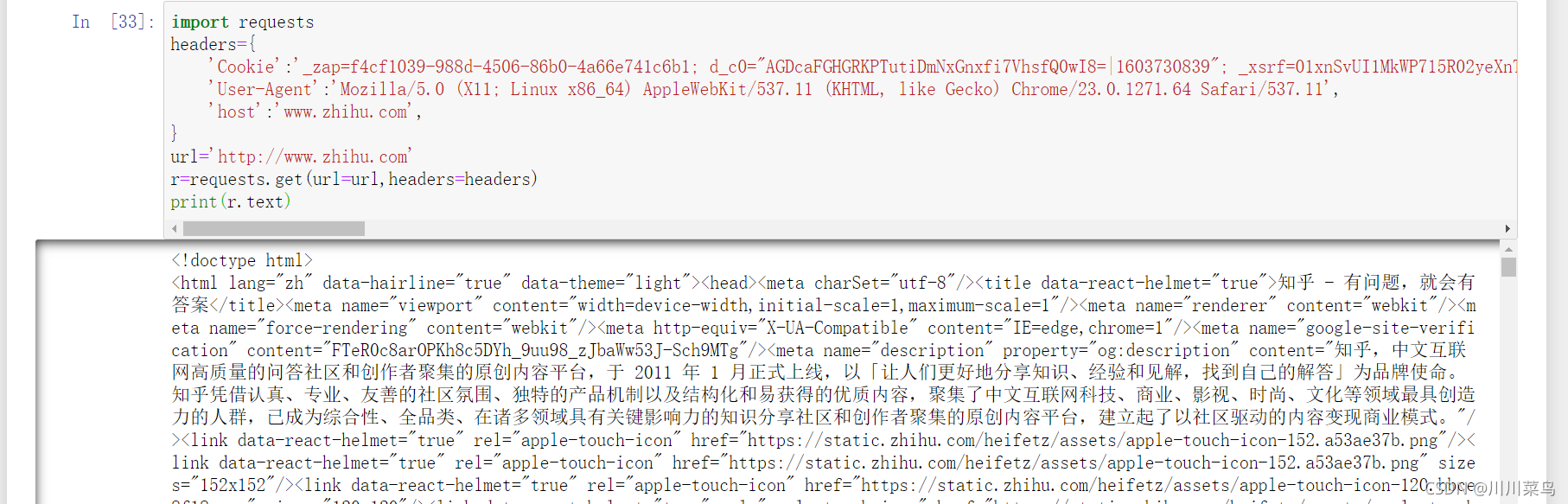
返回结果有知乎里的相关内容,这样就是成功登录知乎了
再提一点session,它可以实现同一个站点进去不同页面:
import requests
s=requests.Session()
s.get('http://httpbin.org/cookies/set/number/147258369')
r=s.get('http://httpbin.org/cookies')
print(r.text)
运行:
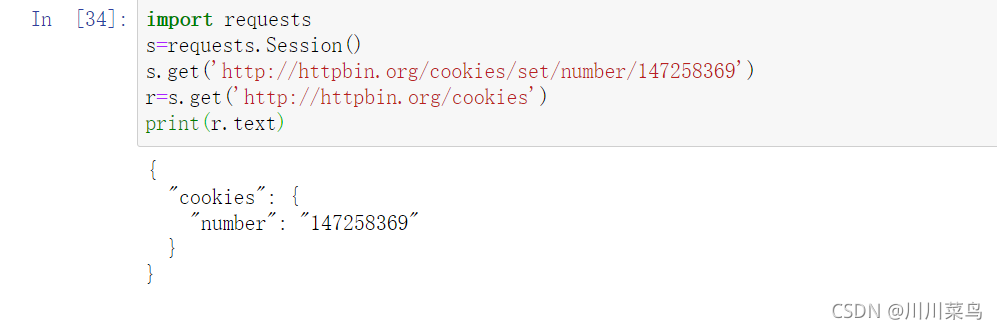
3.6 抓取二进制数据
如果想抓取图片、音频、视频等文件,应该怎么办呢?
图片、音频、视频这些文件本质上都是由二进制码组成的,由于有特定的保存格式和对应的解析方式,我们才可以看到这些形形色色的多媒体。所以,想要抓取它们,就要拿到它们的二进制码。
3.6.1 示例一
下面以 GitHub 的站点图标为例来看一下:
import requests
r = requests.get("https://github.com/favicon.ico")
print(r.text)
print(r.content)
这里打印了 Response 对象的两个属性,一个是 text,另一个是 content。输出如下:
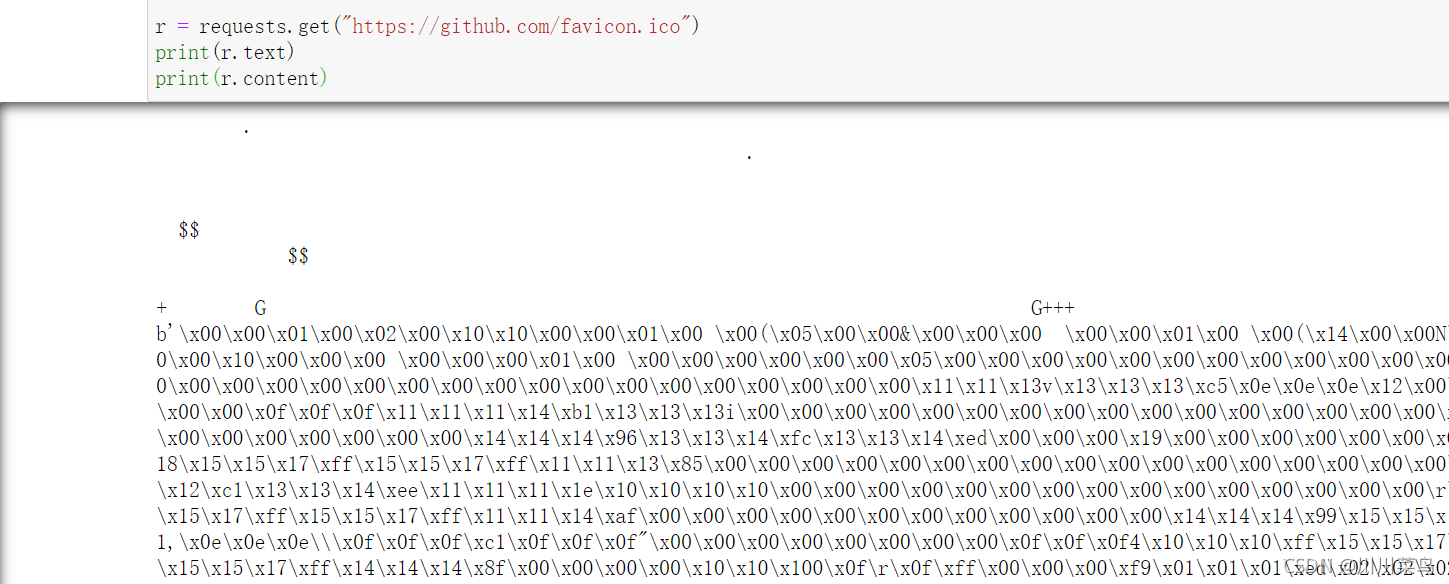
可以注意到,前者出现了乱码,后者结果前带有一个 b,这代表是 bytes 类型的数据。由于图片是二进制数据,所以前者在打印时转化为 str 类型,也就是图片直接转化为字符串,这理所当然会出现乱码。
接着,我们将刚才提取到的图片保存下来:
import requests
r = requests.get("https://github.com/favicon.ico")
with open('favicon.ico', 'wb') as f:
f.write(r.content)
运行即可保存。
3.6.2 示例二
以爬取我自己的头像为例子:
import requests
headers={
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
}
url='https://avatar.csdnimg.cn/9/1/6/1_weixin_46211269_1629324723.jpg'
r = requests.get(url=url,headers=headers)
with open('phpto.jpg', 'wb') as f:
f.write(r.content)
运行即可保存。
3.7 美女私房照爬取( 准备发车)
第一部分:定义要爬取的标签和正在爬取的页数
def UserUrl(theme,pagenum):
url = "https://tuchong.com/rest/tags/%(theme)s/posts?page=%(pagenum)s&count=20&order=weekly" % {'theme': urllib.parse.quote(theme), 'pagenum': pagenum}
#print(url)
return url
第二部分:防止反扒
def GetHtmltext(url):
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36"
}
try:
r = requests.get(url, headers=head, timeout=30)
r.raise_for_status() #如果返回的状态码不是200,就到except中
return r
except:
pass
第三部分:定义获取一个pagenum页面中的所有图集的URL链接的函数
def PictureFatherUrl(user_url): try: raw_data = GetHtmltext(user_url) j_raw_data = json.loads(raw_data.text) #将获取的网页转化为Python数据结构 # print(j_raw_data) father_url = [] #将每个图集的url定义为father_url的一个列表 for i in j_raw_data['postList']: #解析出的j_raw_data是一个多重字典,在这里先将postList字典的内容取出来 father_url.append(i['url']) #然后再取出键为“url”的值 return father_url except: return
第四部分:定义获取一个图集中所有图片的url链接
def PictureUrl(url):
try:
html = GetHtmltext(url)
#利用正则表达式来匹配
url_list = list(re.findall('<img id="image\d+" class="multi-photo-image" src="([a-zA-z]+://[^\s]*)" alt="">', html.text))
return url_list
except:
第五部分:
#定义一个图集中所有图片的下载
def Download(url):
url_list = PictureUrl(url)
for i in url_list:
r = GetHtmltext(i)
file_name = os.path.join(save_path, i.split('/')[-1])
with open(file_name, 'wb') as f:
f.write(r.content)
f.close()
time.sleep(random.uniform(0.3, 0.5)) #为防止被反爬,在这里random了0.3-0.5的数,然后在下载一张图片后,sleep一下
print('下载成功保存至 %s' % file_name)
主函数:
if __name__ == '__main__':
theme = input("你选择的标签(如果你不知道有什么标签,去https://tuchong.com/explore/去看看有什么标签吧,输入不存在的标签无法下载哦):")
pagenum_all = int(input("你要爬取的页数(不要太贪心哦,数字太大会被封IP的):"))
save_path = os.path.join(theme)
m = 0
if not os.path.exists(save_path):
os.makedirs(save_path)
print("我知道你没有创建保存路径,我把文件存在和此脚本同样的路径下的叫做“ %s ”的文件夹下面了" % theme)
for i in range(1, pagenum_all+1):
n = 0
m += 1
print("正在下载第%d页,一共%d页" % (m, pagenum_all))
user_url = UserUrl(theme, i)
father_url = PictureFatherUrl(user_url)
for j in father_url:
n += 1
print("正在下载第%d套图,一共%d套图" % (n, len(father_url)))
Download(j)
time.sleep(random.randint(6, 10)) #同样为了反爬,也random了6-10之间的数,更真实的模拟人的操作
完整源代码:
#coding=gbk
"""
作者:川川
时间:2021/10/11
"""
#study group:428335755
import os
import re
import json
import requests
import time
import urllib.parse
import random
#定义要爬取的标签和正在爬取的页数
def UserUrl(theme,pagenum):
url = "https://tuchong.com/rest/tags/%(theme)s/posts?page=%(pagenum)s&count=20&order=weekly" % {'theme': urllib.parse.quote(theme), 'pagenum': pagenum}
#print(url)
return url
#利用requests使用get方法请求url,使用User-Agent是为了防止被反爬,这样使得我们的爬取行为更像人的行为
def GetHtmltext(url):
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36"
}
try:
r = requests.get(url, headers=head, timeout=30)
r.raise_for_status() #如果返回的状态码不是200,就到except中
return r
except:
pass
#定义获取一个pagenum页面中的所有图集的URL链接的函数
def PictureFatherUrl(user_url):
try:
raw_data = GetHtmltext(user_url)
j_raw_data = json.loads(raw_data.text) #将获取的网页转化为Python数据结构
# print(j_raw_data)
father_url = [] #将每个图集的url定义为father_url的一个列表
for i in j_raw_data['postList']: #解析出的j_raw_data是一个多重字典,在这里先将postList字典的内容取出来
father_url.append(i['url']) #然后再取出键为“url”的值
return father_url
except:
return#定义获取一个图集中所有图片的url链接
def PictureUrl(url):
try:
html = GetHtmltext(url)
#利用正则表达式来匹配
url_list = list(re.findall('<img id="image\d+" class="multi-photo-image" src="([a-zA-z]+://[^\s]*)" alt="">', html.text))
return url_list
except:
pass
#定义一个图集中所有图片的下载
def Download(url):
url_list = PictureUrl(url)
for i in url_list:
r = GetHtmltext(i)
file_name = os.path.join(save_path, i.split('/')[-1])
with open(file_name, 'wb') as f:
f.write(r.content)
f.close()
time.sleep(random.uniform(0.3, 0.5)) #为防止被反爬,在这里random了0.3-0.5的数,然后在下载一张图片后,sleep一下
print('下载成功保存至 %s' % file_name)
#定义主函数
if __name__ == '__main__':
theme = input("你选择的标签(如果你不知道有什么标签,去https://tuchong.com/explore/去看看有什么标签吧,输入不存在的标签无法下载哦):")
pagenum_all = int(input("你要爬取的页数(不要太贪心哦,数字太大会被封IP的):"))
save_path = os.path.join(theme)
m = 0
if not os.path.exists(save_path):
os.makedirs(save_path)
print("我知道你没有创建保存路径,我把文件存在和此脚本同样的路径下的叫做“ %s ”的文件夹下面了" % theme)
for i in range(1, pagenum_all+1):
n = 0
m += 1
print("正在下载第%d页,一共%d页" % (m, pagenum_all))
user_url = UserUrl(theme, i)
father_url = PictureFatherUrl(user_url)
for j in father_url:
n += 1
print("正在下载第%d套图,一共%d套图" % (n, len(father_url)))
Download(j)
time.sleep(random.randint(6, 10)) #同样为了反爬,也random了6-10之间的数,更真实的模拟人的操作
运行:按照提示输入回车



当然,难道我的心只有小姐姐私房照?NONONO!你只要输入该网任意一个标签的都可给下载下来,比如模特?你可以测试一下。
四、 POST 请求
前面我们了解了最基本的 GET 请求,另外一种比较常见的请求方式是 POST。
4.1 数据表单提交
使用 requests 实现 POST 请求同样非常简单,示例如下:
import requests
data = {'name': 'germey', 'age': '22'}
r = requests.post("http://httpbin.org/post", data=data)
print(r.text)
这里还是请求 http://httpbin.org/post,该网站可以判断如果请求是 POST 方式,就把相关请求信息返回。
运行结果如下:
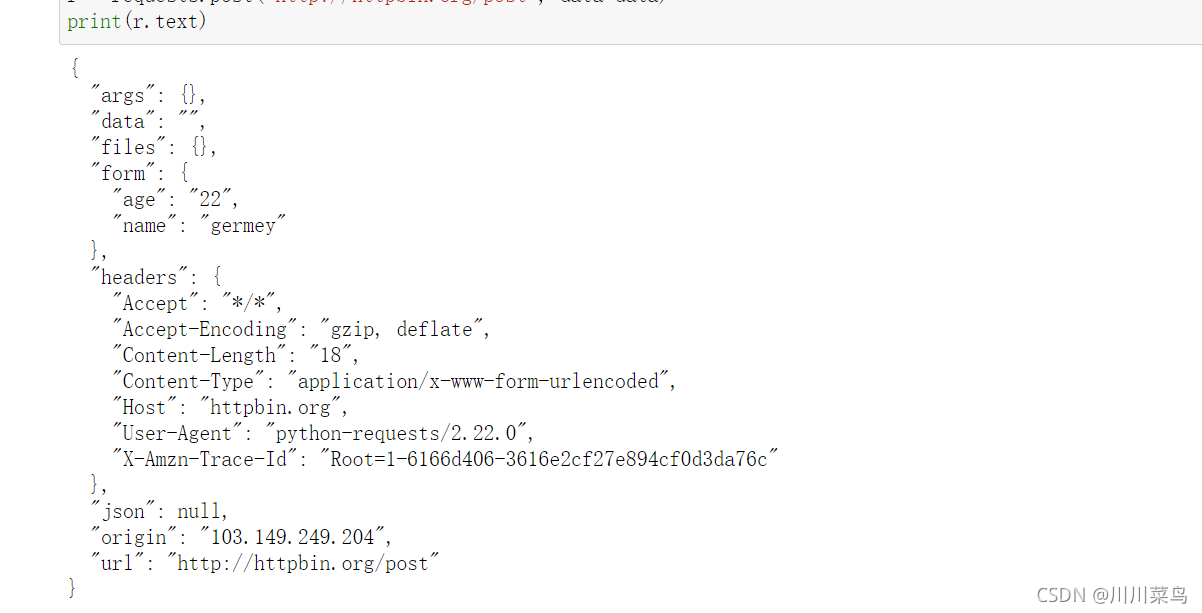
可以发现,我们成功获得了返回结果,其中 form 部分就是提交的数据,这就证明 POST 请求成功发送了。
4.2 添加请求头
代码如下:
import requests
import json
host = "http://httpbin.org/"
endpoint = "post"
url = ''.join([host,endpoint])
headers = {"User-Agent":"test request headers"}
r = requests.post(url,headers=headers)
print(r.text)
运行:
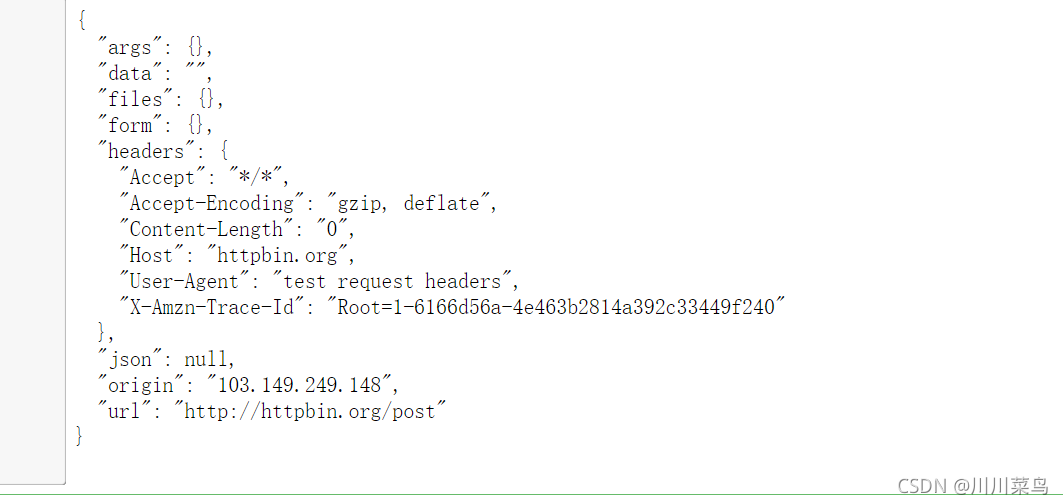
可以看到User-Agent部分为我们添加的自定义请求头。
4.3 提交json
假设我想提交json格式的内容:
# -*- coding:utf-8 -*-
import requests
import json
host = "http://httpbin.org/"
endpoint = "post"
url = ''.join([host,endpoint])
data = {
"sites": [
{ "name":"test" , "url":"https://blog.csdn.net/weixin_46211269?spm=1000.2115.3001.5343" },
{ "name":"google" , "url":"https://blog.csdn.net/weixin_46211269/article/details/120703631?spm=1001.2014.3001.5501" },
{ "name":"weibo" , "url":"https://blog.csdn.net/weixin_46211269/article/details/120659923?spm=1001.2014.3001.5501" }
]
}
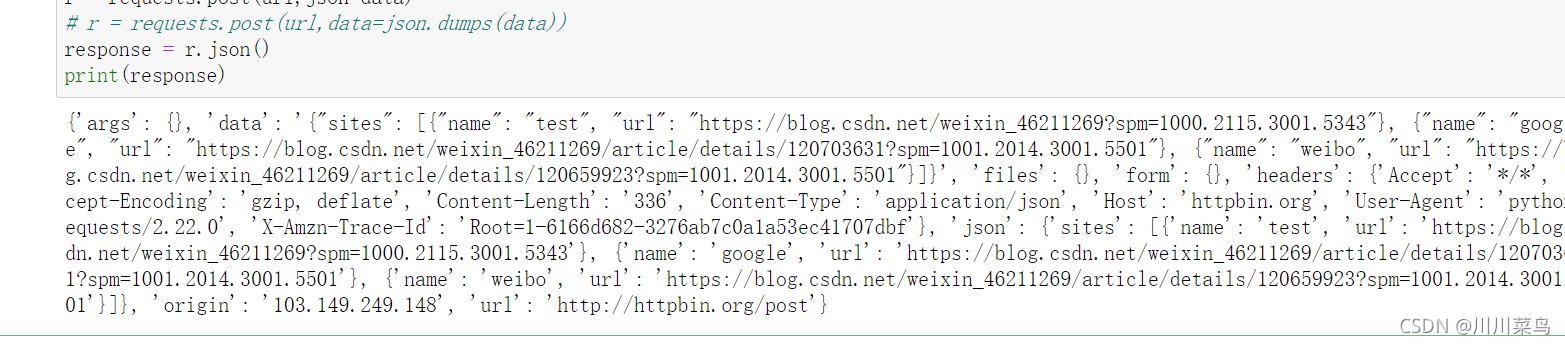
r = requests.post(url,json=data)
# r = requests.post(url,data=json.dumps(data))
response = r.json()
print(response)
运行如下:
4.4 普通文件上传
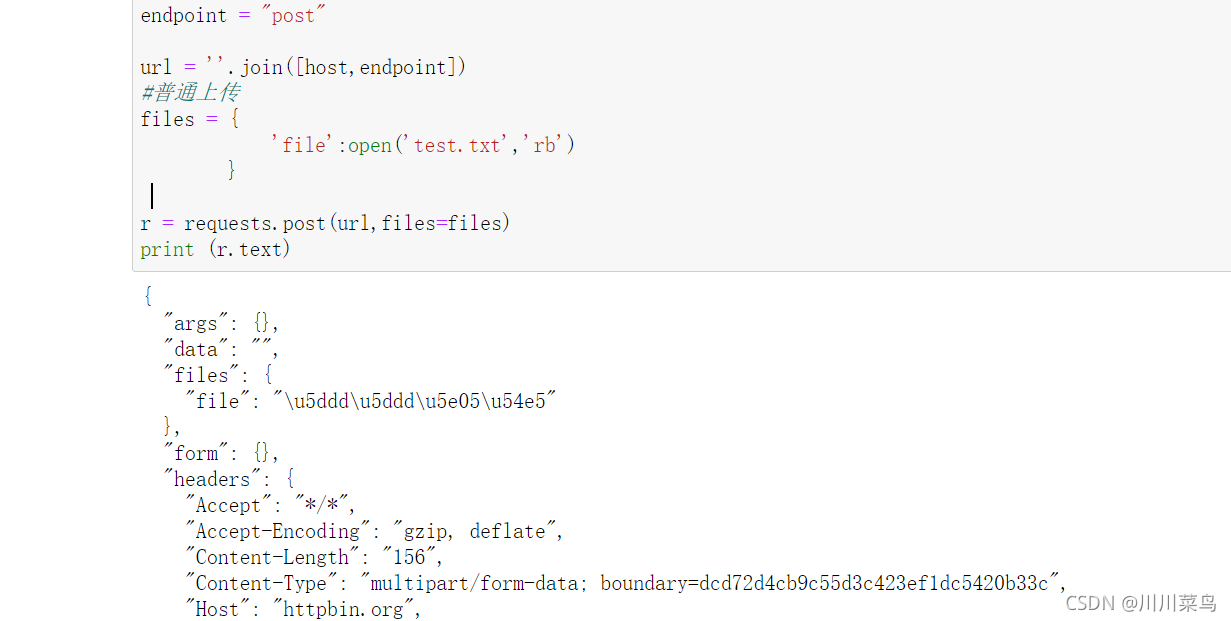
代码:
# -*- coding:utf-8 -*-
import requests
import json
host = "http://httpbin.org/"
endpoint = "post"
url = ''.join([host,endpoint])
#普通上传
files = {
'file':open('test.txt','rb')
}
r = requests.post(url,files=files)
print (r.text)
不要忘了自己定义一个test.txt文件
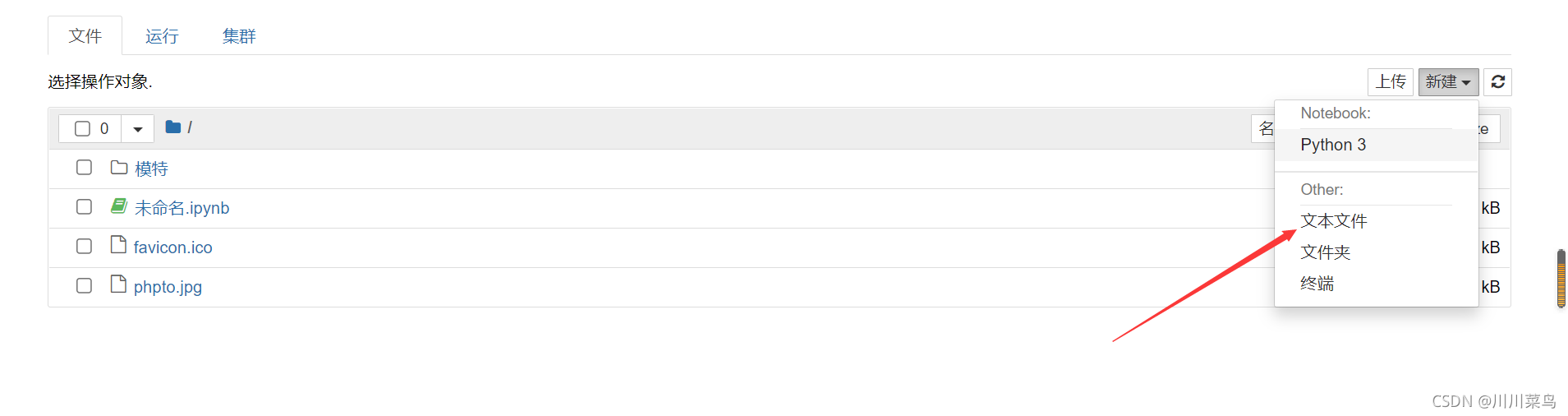
内容为:川川帅哥,保存即可。
选中重命名:
运行如下:
四、粉丝福利
对于个人的忠实粉丝,我随机抽取送如下书籍一人一两本。这本书从自动化测试理论入手,全面地阐述自动化测试的意义及实施过程。全文以Python语言驱动,结合真实案例分别对主流自动化测试工Selenium、Robot Framework、Postman、Python+Requests、Appium等进行系统讲解。通过学习本书,读者可以快速掌握主流自动化测试技术,并帮助读者丰富测试思维,提高Python编码能力。

五、总结
看一下最终的文件夹:

本篇为requests基础篇,如果本篇内容大家支持多,我尽快出高级篇。有的人要问我为啥不教urlib?个人倒是觉得这个有点被淘汰了,所以我就不讲了,大家觉得有必要讲urlib可以留言,我看人数要不要补充。
👇🏻 加入私人粉丝群 可通过搜索下方 公众号 发送关键词: 进群